


We Forgot to Evaluate EHRs Throughout the Lifecycle. AI Governance is Our Do-Over
What EHRs taught us about (lack of) health tech evaluation, and what AI is forcing us to do better

The late 2000s were all about quality metrics. The Physician Quality Reporting System (PQRS, which has morphed into programs like MIPS) was introduced to evaluate doctors on adherence to specific measures, and hospital administrators suddenly had to figure out how to use Excel to present their quality scores. The budding EHRs and the HITECH Act in 2009 meant that there was now easily accessible data to evaluate clinicians.
Ironically, we forgot to use that same data to evaluate the EHRs.
Early EHRs promised improved efficiency, better access to information, less time spent hunting down charts. You might also remember the long implementation timelines, the skyrocketing costs, and the sense that after all that investment, starting from scratch just wasn’t an option.
In some ways, the EHR has worked how we expected. When I ran a pain clinic, I could see when my patients were getting prescriptions from other providers. That would have been impossible pre-EHR. But for many clinicians, the EHRs contributed to exhaustion and burnout.
Throughout the changes, we never actually asked the most important question:
Are patients and clinicians better off than they would have been without this?
You’d think we’d be experts at evaluating health tech after 20 years of practice. Instead, it seems like we’re starting from scratch.
We evaluated doctors using performance metrics enabled by the EHR, but we never really evaluated the EHR itself. Maybe after all the effort to implement the EHR, the system didn’t really want to know.
We can’t afford to make that mistake again.
We didn’t treat EHR, or any health tech tool, as something that needs continuous evaluation through a lifecycle. The buyers, the health system, didn’t seem to have any real expectation of being presented with clinical outcome improvements. This contrasts with the way we expect physicians to be evaluated continuously through medical school, residency, and throughout their careers with MIPS, OPPEs, and other evaluations.
One of the core problems with current AI governance documents is that they’re too often treated as retrospective checklists. It’s something vendors complete after building the tool, rather than something that shapes development from the start. The result is a compliance exercise that feels disconnected from product reality. Even when teams are being thoughtful about clinical risk and workflow, they still have to retrofit their work into templates that weren’t designed to guide development in real time. This post-hoc approach doesn’t just waste time; it misses the point. Governance shouldn’t be a hurdle to clear after the fact. It should be an integral part of the build process: guiding design decisions, surfacing potential harms early, and helping teams prioritize what matters most. Until our frameworks become useful during development, the governance structure won’t be truly meaningful.
Existing Healthcare AI Lifecycle Frameworks
There are many ways to describe the healthcare AI evaluation lifecycle. My issue with most of them is that they’re too high-level to be practical.
CHAI has a nice 6 step lifecycle evaluation framework that includes:
Define Problem and Plan
Design the AI system
Engineer the AI solution
Assess
Pilot
Deploy and Monitor

Their suggestions are great, but they’re fairly vague. For example, for the “Assess” step for Safety, it includes “conduct verification and validation activities”. That sounds like a generally good idea, but the next step of translating that into action is where it gets really challenging.
The ELICIT framework developed by researchers at the University of Utah has a series of high-quality questions that guide lifecycle evaluation. But it was only published in 2023, over 20 years after EHRs were introduced. I’ve seen many similar questions in AI governance packets related to expected outcomes, like “Who are the relevant end users? How will they be affected?” They also give some “Exemplar methods” like “Systematic input from relevant stakeholders”.

This framework is a good start for concrete evaluation methods for EHRs, and a similar approach is needed for healthcare AI products. These tools are more powerful, more complex, and often less transparent than the tech that came before. AI has raised the bar because its risks are harder to ignore. But many health tech products we already use would fail today’s AI governance questions. We just never thought to ask them.
Additionally, we need specific checks for AI tools: subgroup performance, hallucination risk, model drift, explainability, and more. But the core structure of evaluation should apply to everything.
Most people in healthcare have seen some version of the lifecycle diagram, and ELICIT’s is nicely broken up into impacts on society, users, and AI, though I would love to have a “patient” row here.
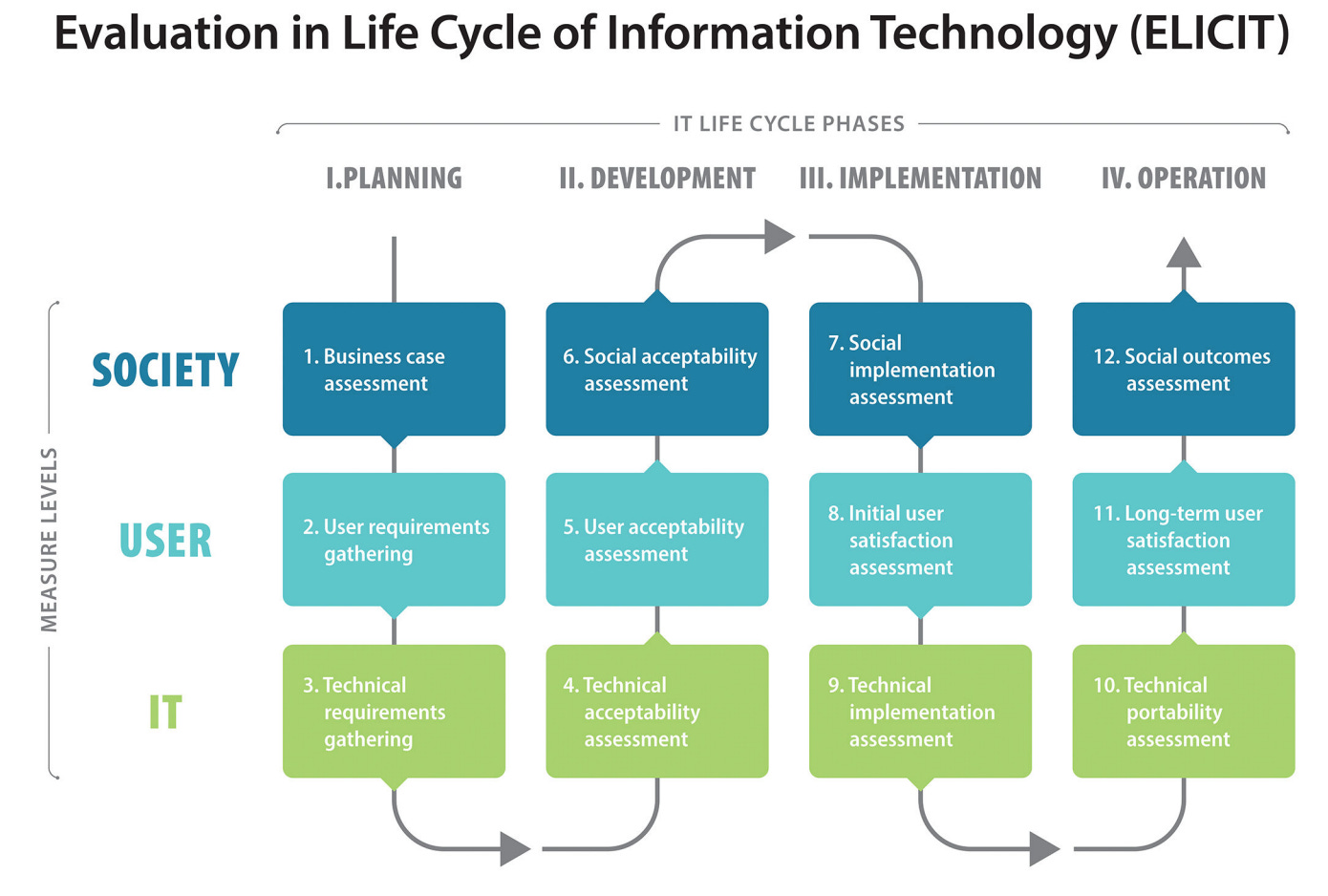
My favorite ELICIT question is “Do users find the innovation software acceptable, usable, and enjoyable (perceived enjoyment)?” Imagine evaluating EHRs on enjoyment!
A simple structure: Lifecycle × Risk Category × Better Questions
We need lifecycle evaluation, but one that’s not retrospective, vague, or built only for post-hoc compliance. I’ve developed a framework that breaks the lifecycle into concrete, stage-specific risks: misuse, mistakes, and structural failures. Each maps to questions you can actually answer while building.
As I mentioned in a previous post, I group risks into three domains:
Misuse (deliberate misuse, patient data abuse, financial manipulation)
Mistakes (errors made by AI or by users like bias, hallucinations, user error)
Structural risks (workflow misalignment, missing oversight, poor integration)
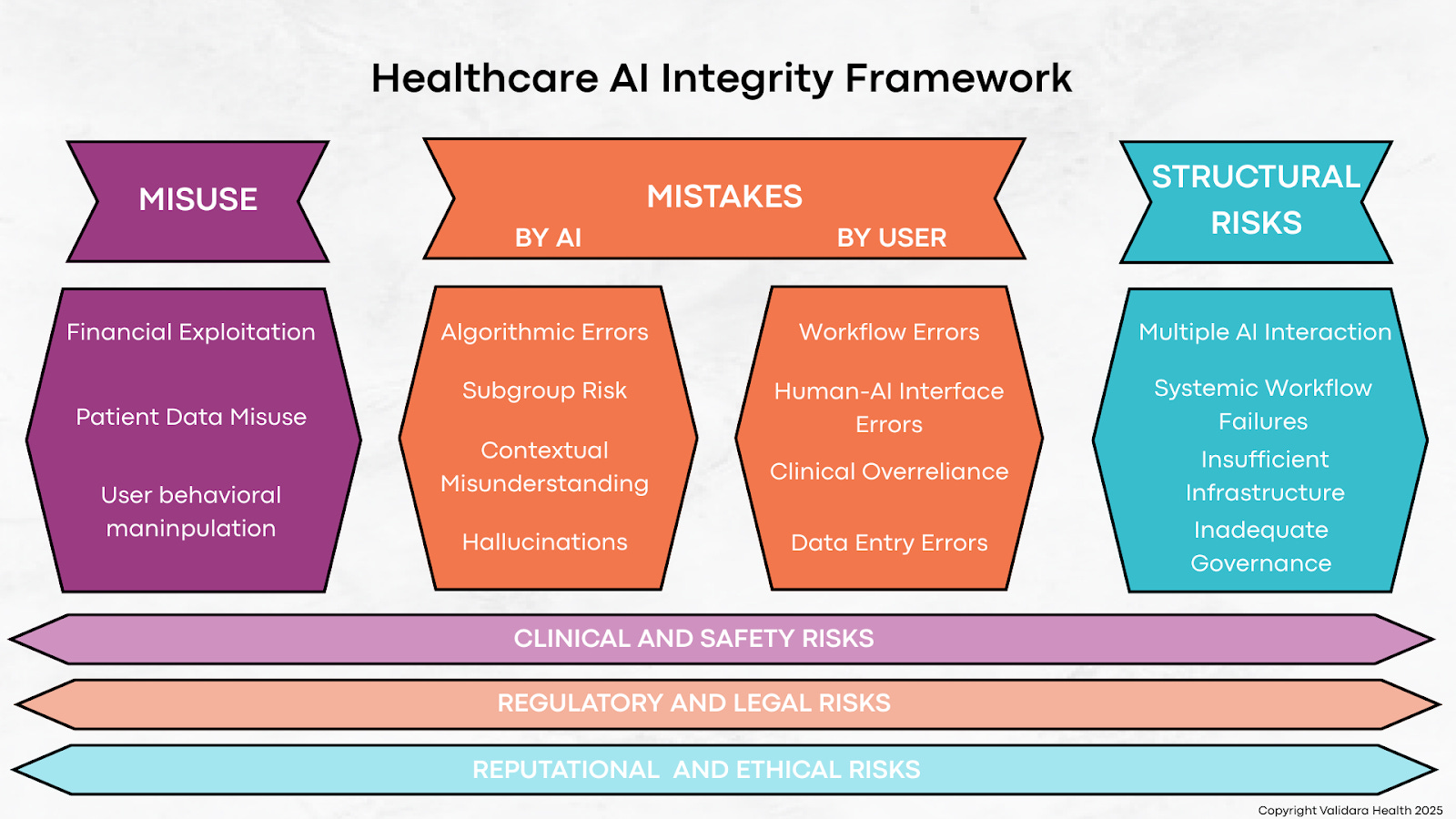
I’ve mapped those onto the lifecycle to give AI vendors more clear guidance about what to ask at which stage. My stages are more geared toward those building products rather than the health systems implementing them, with the hope of incorporating these questions as early as possible in the process (coming soon!)
Each stage has different risks, and different questions you should be asking.

For example:
In design, have you mapped where human oversight is needed, and what outcomes would improve patient (and clinician) well-being?
During in silico testing, have you run public benchmarks and had clinicians use the tool in a simulated environment?
During the pilot, how are you collecting and synthesizing real-time feedback from end-users?
In deployment, are you tracking override rates, performance drift, and user-reported issues? Even more important, are you tracking outcomes that matter to clinicians and patients?
In monitoring, are you transparently logging changes and re-checking for harm?
These are the kinds of practical, hands-on questions that can help develop a great product. And they help answer the question we never asked about EHRs:
Is this actually making care better?
Sarah, I agree that we need routine, rigorous evaluation of health tech across its lifecycle. EHRs taught us what happens when that doesn’t occur, and AI makes this need even more urgent.
However, I disagree that such evaluation isn’t being done. The tools and frameworks exist, but most organizations haven’t prioritized them.
For EHRs specifically, there are many resources already in place, including:
SAFER Guides
HIMSS EHR-AM and AMR-AM
Leapfrog CPOE Testing
ARCH Collaborative
Patient Voice Collaborative
EHR vendor programs like GoldStars and Honor Roll
Predictive model working groups
These tools are ready to measure EHR performance; the missing piece is operational commitment. FYI, we do all of the above regularly—a lot of work, but we learn SO much and get better every time!