


The Healthcare AI Triad: Data
Understanding how data affects healthcare AI

“As ML healthcare systems are deployed, the greatest challenges in implementation arise from problems with the data: how to efficiently deliver data to the model to facilitate workflow integration and make timely clinical predictions? Furthermore, once implemented, how can model robustness be maintained in the face of the inevitability of natural changes in physician and patient behaviours?” - Zhang et al, Nature Bioengineering
For healthcare AI models to be accurate, they need a very large amount of data from a diverse group of people, and preferably with accurate labels. As you might imagine, getting that data is much harder than scraping the web. Many of the public datasets are limited to one group like Medicare beneficiaries or VA patients, which can cause the model to perform poorly and not be generalizable. There are also many datasets from claims data, which lack clinical nuance. Most healthcare organizations don’t have the infrastructure to prepare their data to adequately train and validate AI models, which makes it functionally useless. Unless, of course, they partner with a company that provides that service.
Healthcare data is a multibillion dollar commodity
Healthcare data has become big business, to the point that some health tech companies provide a service with the goal of monetizing (read: selling) patient information, since the data can be worth more than the clinical revenue. Many large companies already do this:
From the Lancet: Major Commercial Health Datasets and Vendors
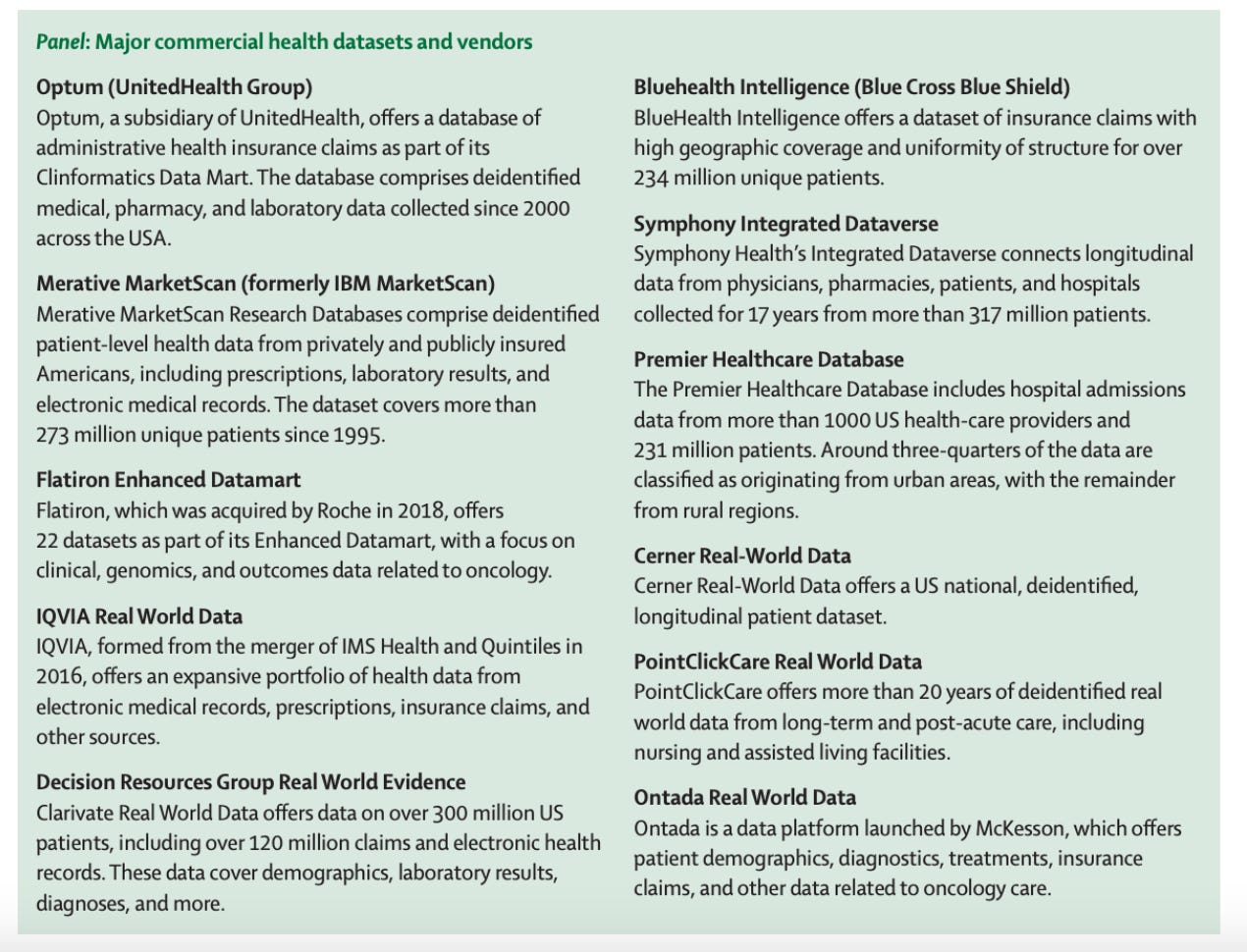
Private healthcare databases present major unresolved issues
Currently about half of AI models are trained on private data. But using private databases presents serious issues that haven’t been resolved:
The companies or researchers may use the data in different ways than anticipated, which makes any notion of patient consent challenging
Companies can transfer patient data to different countries easily, despite those countries’ differing privacy laws for PHI.
When Google took control of DeepBrain’s app, it effectively took data from UK NHS patients and transferred it to the US
It’s nearly impossible for patients to claim data back or refuse use for specific purposes once it’s in the hands of a private company
Data needs to be evaluated to see if it’s appropriate for the use case, and often private data is opaque
Private data vendors usually don’t want people probing deeply into their datasets for fear of loss of competitive advantage.
However, it’s difficult or impossible to ascertain bias and generalizability without reviewing the training data of a model.
Public Healthcare Databases
This table from AltexSoft gives a nice overview of some of the major public healthcare databases. There are some great options (MIMIC, for example) that have been widely used for AI models, but still suffer from issues stemming from the narrowness of their patient populations.

Healthcare Data Breaches
Data breaches are becoming more common in all sectors including healthcare, and in all geographic locations. Below is data just for the US, and you can see that there has been a rapid rise in the past 3-5 years (2023 is low because it’s only 6 months of data). As more healthcare data goes outside local servers, we can expect more data breaches.
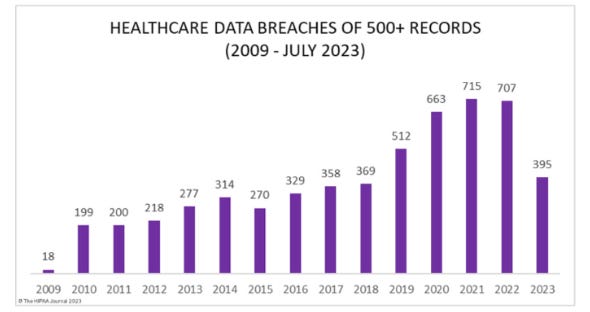
Graphic from The HIPAA Journal
Re-identification of data
Reidentification of de-identified patient data with AI models is also a major issue that is probably not getting as much attention and regulation as it should.
One study found that 95% wearable physical activity data from adults could be reidentified “despite data aggregation and removal of protected health information.” Some authors go so far as to say that the risk of re-identification is so high that it effectively nullifies the anonymization of records.
HIPAA was passed in 1996, which is basically the Ice Ages in terms of computation and machine learning (for context for those under 40, 1996 was the year my family got a computer). So it’s not surprising that advances in technology mean modifications are needed to maintain the spirit of the law.
Fundamental Challenges with Clinical Data
Sampling frequency: There may be a lot of blood pressures measured in a hour, or none, depending on the setting and patient condition
Data quality: There may be incorrect inputs or areas of the chart that have more accurate versions of the same information
Data formatting: Most clinical data is unstructured
Differing technical specifications: Each EHR platform has its own clinical terminology and technical capabilities
Data shifts: Medical recommendations and practice change, and data can vary widely due to:
“Institutional differences (such as local clinical practices, or different instruments and data-collection workflows)
Epidemiological shifts (COVID, for example)
Temporal shifts (for example, changes in physician and patient behaviours over time
Differences in patient demographics (such as race, gender and age).”
Sources of data go beyond information about patients
Many medical applications will need actual medical knowledge, not just clinical practice history, in order to do what we want them to do. Books, society guidelines, recent literature, conference proceedings: all these sources of information contribute to medical decision-making. Getting them all into a model, especially given the paywalls for many journal articles and the increasing frequency of lawsuits about copyright infringement of AI training material, is not a minor issue.
Data availability in the health sciences
In 2019, the Department of Health and Human Services convened a panel to discuss issues related to “sharing and utilizing health data for AI applications.” Much, but not all, of the information in the table below is included in that report.

Barriers to using healthcare data
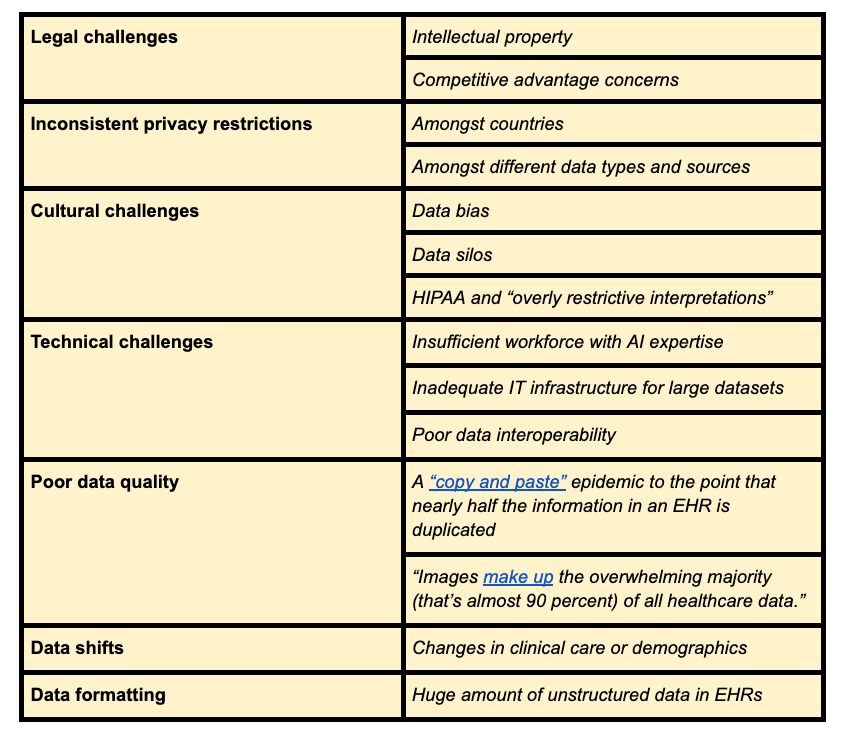
Summary
Clearly there is a lot of work to be done at every level to ensure patient safety and confidentiality when sharing data and sculpting the data to fulfill the promise of AI. Physicians need to be aware of these issues and advocate for datasets that are both respectful and robust.
So far this month we’ve discussed:
Data in the healthcare AI triad
Next week we’ll discuss
The future of the AI triad