


The Healthcare AI Triad: Compute in the Clinical Setting
Understanding how limitations on compute impact healthcare

Compute in the clinical setting
Healthcare systems are moving towards owning, using, and managing huge amounts of data, to the point that they’re becoming much more similar to other large data-intensive industries like banking. But how does compute impact healthcare, both from a clinical and systems perspective?
Today we’ll discuss:
Edge computing
Energy use vs energy efficiency
Cost of data storage and AI use
The high-powered AI chips we discussed last week are used in healthcare for purposes like medical imaging, and are usually cloud-based. This works fine for medical imaging in a traditional setting with a radiologist in front of a computer and a strong internet connection.
But as AI becomes more common, we have to think about how to deliver AI with smartphones or tablets and a WiFi connection instead of a network. Delivering these technologies could be especially powerful in low-resource countries where healthcare providers lack all of the resources to read a chest X-ray: computer, internet cable, and radiologist.
There’s an inevitable lag associated with sending information to the cloud, processing it, and sending it back. In remote patient monitoring of a potentially deadly heart rhythm or the onset of a seizure, for example, that lag may be too long. Additionally, AI queries are often 10 times more expensive than standard requests, which can become prohibitive.
If the use cases were limited to low resource countries and a handful of patient monitoring scenarios, I doubt industry would be rushing to provide solutions. However, the same technology can be used for making shopping and restaurant predictions, so capitalism provides a solution.
Edge computing
Qualcomm considers the move to running AI on smartphones to be analogous to the change from mainframes in the 1960s to cloud computing now. It makes tensor processing units, or TPUs, which are called “edge processors” because they run “on the edge”, meaning on devices instead of in the cloud. Recently Qualcomm signed a deal with Meta to allow Llama 2 to run on Qualcomm chips for phones starting in 2024. Because Llama is a smaller model than ChatGPT, it makes sense for it to be better suited for a smartphone.
Qualcomm calls using local (phone/tablet) and cloud-based AI “hybrid AI”:
“If the model size, prompt, and generation length [are] less than a certain threshold,” then the AI can run just on the phone.
The queries can also run on both the phone and cloud, with the cloud-based version helping to correct the phone version along the way if needed
It’s important to note that Qualcomm’s stock has had a pretty mediocre performance compared to the rest of the tech world so they’re motivated to paint an optimistic picture of what they can do. But others also point out that running LLMs on the device instead of the cloud has some advantages, including:
Better privacy, since you’re not sending personal information on your device into the cloud. Especially important in healthcare.
Better recommendations, because it can use the information like restaurant and photo searches that are stored locally on a phone. Important in healthcare for devices running continuous data like continuous glucose monitors and pacemakers.
Don’t have to have cell service for it to work
You pay for the AI capability when you buy your phone with the processor in it; there aren’t ongoing costs to access the cloud-based AI model
However, one paper notes that edge devices (in healthcare, these might be pacemakers or wearables) don’t yet have the capacity to learn without frequent communication with the cloud, which then introduces the security and energy issues of any cloud-based system.
Energy use is rising more quickly than energy efficiency
Of course, this improved technology and associated increased compute isn’t cheap, either monetarily or in energy usage.
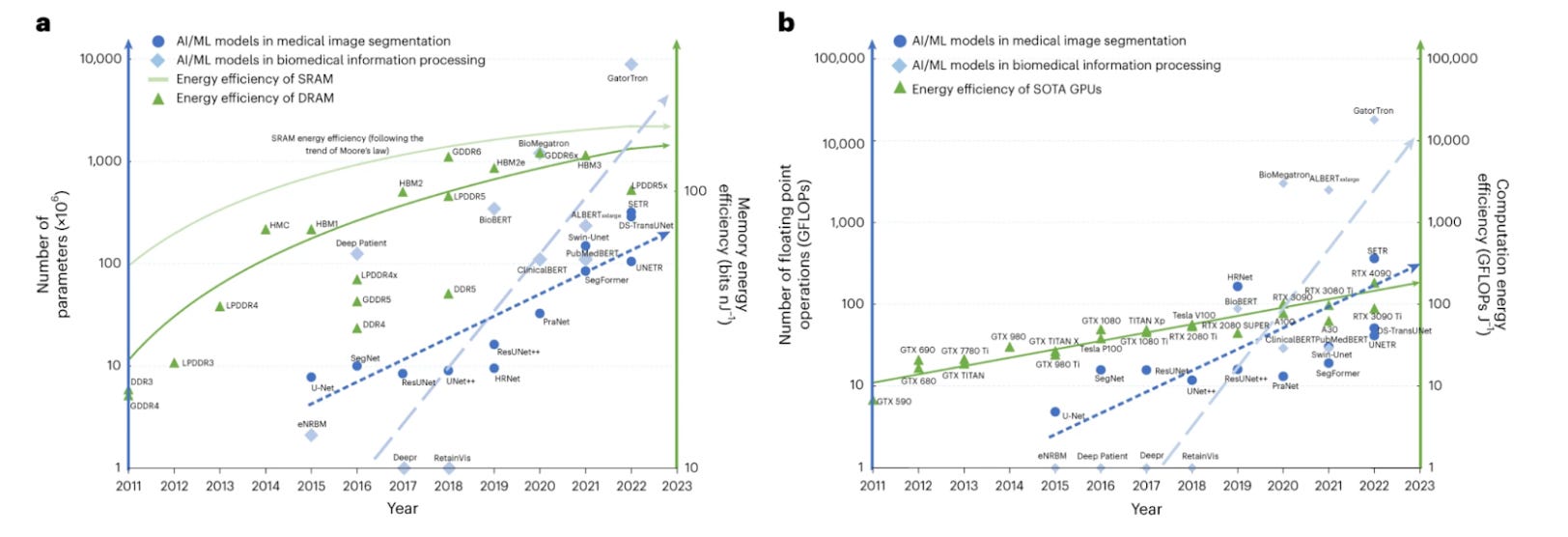
This excellent graphic has a lot going on, but focus just on the dashed blue lines going up at a steep angle: that’s the energy use for medical imaging (left) and for EHR data extraction (right). Now look at the solid lines in both graphs, which are basically flat: that’s the energy efficiency of the memory or GPUs in the computer. You can see that the energy use is rising rapidly but the efficiency is following Moore’s law.
From Jia et al, Nature Machine Intelligence 2023
Cost is of storage and AI is an increasing concern
The same Nature article describes the incredible increase in storage demands for healthcare data. Healthcare institutions usually keep data:
On-campus with a network attachment
Up to $3,000 per terabyte per year
One high-resolution histopathology slide is about 16GB. This means 62 of those images would be one terabyte.
Maintained by a cloud storage vendor
Up to $3,600 per terabyte per year
Risk of exposure of health data with commercial vendors, and rarely used
The cost issue for the amount of compute in healthcare AI (including storage broadly in that category) will vary drastically depending on the application and setting. I found one article that attempted to get at the actual costs of using AI for radiologists in Europe:
Upfront costs for commercial AI vendors:
$40K for a server
$20K for hardware
$20K for software license annually
The article compared that to a hospital-developed solution, which it estimated at $800K plus many unpaid hours of employee work. It also noted that AI is not specifically reimbursed in many countries; CMS has approved reimbursement for about 3.6% of AI products.
There’s a real dearth of information about exactly how much AI implementation has cost healthcare systems thus far, and how much it’s expected to cost in the future. McKinsey estimates there’s an opportunity for $1 trillion in tech-enabled efficiency improvements by 2027, but doesn’t specify how much healthcare systems will pay for that increased efficiency. Healthcare systems clearly need systematic investment in infrastructure to facilitate AI in the future, but our fragmented system is not built for these kinds of big projects.
So far this month we’ve discussed:
Compute in the clinical setting
In upcoming weeks we’ll discuss:
Data in the healthcare AI triad
The future of the AI triad