


The Basics of Benchmarking in Healthcare AI
Why physicians are easier frameworks for AI benchmarks than EHRs

What is benchmarking?
Benchmarking in AI can mean many different things, as the term suffers from a common problem in AI where the same word is used to describe various concepts (see “dataset”, “validation”, “experiment”, etc).
The dictionary definition of benchmark is:
evaluate or check (something) by comparison with a standard.
This definition requires that a standard exists, which in AI benchmarking it often doesn’t. Dan Hendrycks was inspired to create hard questions for AI models to answer way back in 2020 during a conversation with Elon Musk, and came up with the MMLU. This was developed by Dan Hendrycks and his group at Berkeley and is a compilation of a bunch of standardized tests. This is common for benchmarks: using questions and answers that already exist and have been validated makes a lot of sense. Also, people already know what the questions equate to for human performance, so a human baseline already exists (we’ll come back to this concept).
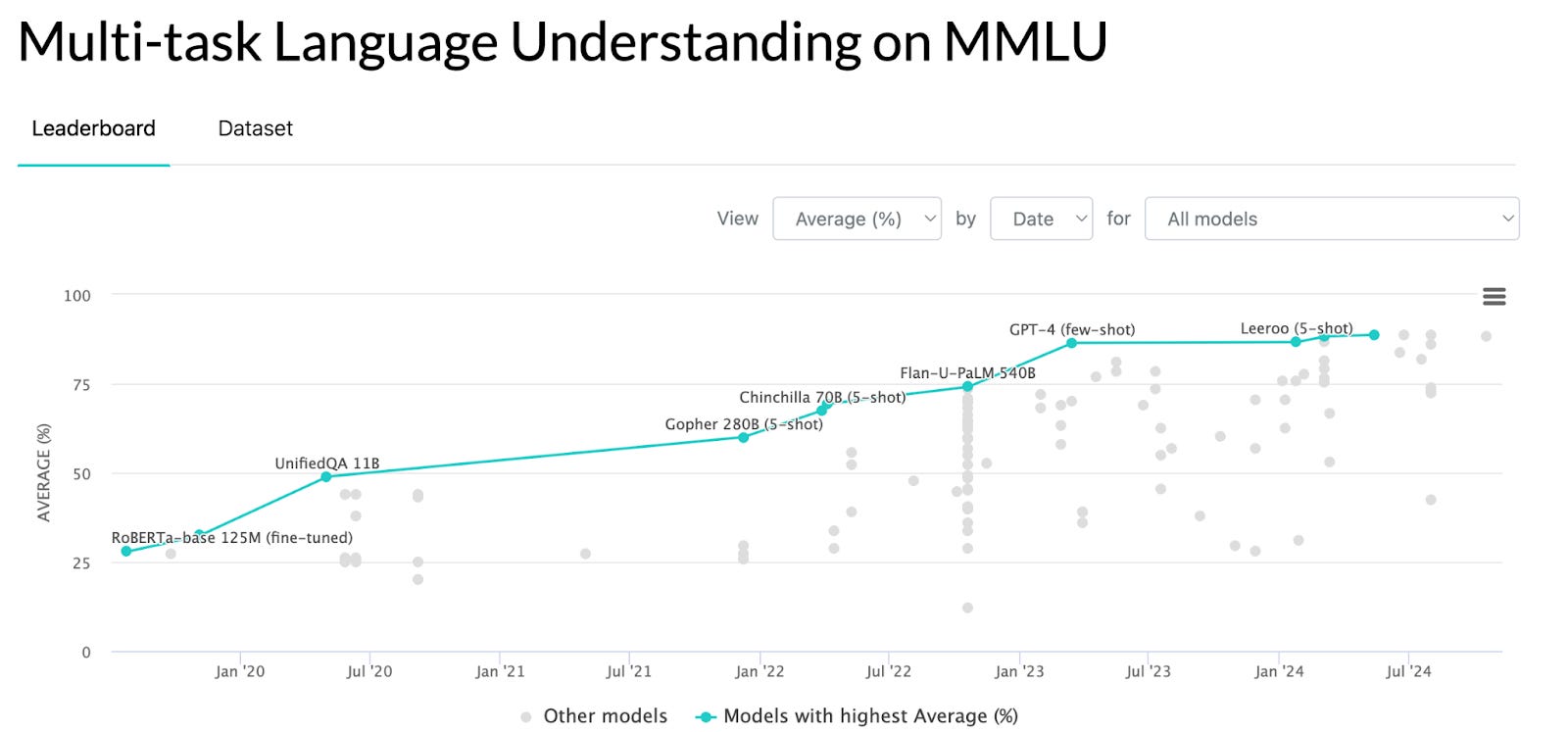
Why is benchmarking important?
Benchmarking helps us compare AI systems in a standardized way. It’s actually quite similar to comparing humans with standardized tests. So much so that many of the first AI benchmarks (including some of the MMLU questions) were from medical standardized tests. The MedQA benchmark, for example, has USMLE questions, and the MedMCQA has 2,400 healthcare questions from the Indian health-related entrance exams.

https://paperswithcode.com/sota/question-answering-on-medqa-usmle
If you’re reading this, I’m going to guess you’re better than average at standardized testing. But you are still statistically unlikely to score higher than Med-Gemini.
Many of the same upsides and concerns about standardized tests apply to AI benchmarking: they don’t give a full picture of performance, training the AI system (or student) on similar material provides a large advantage but might not be indicative of true knowledge, etc.
The most valuable part of benchmarking is to make an “apples to apples” comparison and especially to be able to view it in an understandable format. AI systems may be able to understand a stream of unprocessed data, but we humans are still stuck with preferring visuals and stories. Benchmarks let us quickly assess how a model performs relative to other AI systems.
Healthcare loves benchmarking!
But knowledge/standardized testing benchmarks are just one kind of benchmark.
In medicine we’re very familiar with the idea of benchmarking. In fact, we are personally benchmarked all the time. It’s called performance metrics or efficiency metrics or clinical quality, but there are algorithms comparing us to other doctors all over the place: how many patients we see per hour, how often we follow clinical practice guidelines, and how much our patients like us. Some of these are public via the Medicare.gov website (which used to be aptly named ‘Physician Compare’), and others are specific to our health systems like metrics related to Ongoing Professional Performance Evaluations. Some specialties like surgery tend to have many more metrics publicly available than others like anesthesiology.
You can see my lone public metric here:


Interestingly, Dr. Ernest Codman is often described as the father of benchmarking in medicine for the “End Result System” he developed, which was basically a way to keep track of surgical outcomes. It was so controversial that he was forced to resign from MGH in the early 1900s. But he was so committed to the idea that he later opened a clinic based on the concept of measuring outcomes that caused him to go bankrupt. His system formed the basis for the American College of Surgeons’ tracking system that then became everyone’s favorite benchmarking organization, the Joint Commission.

I wonder what Dr. Codman would have thought about Yelp physician reviews
Of course, clinical trials and non-inferiority studies are also types of benchmarks and medicine could barely function without them. How would we know if one medicine is better than another? How would we decide which device to insert?
Applying benchmarks to healthcare AI
This brings us to a major question: how do we benchmark healthcare AI?
First, we would probably want to look towards examples of healthcare IT benchmarks in general. EHR benchmarks, for example, must be plentiful, right?
It turns out there are far fewer public evaluations of EHRs than there are for physicians. The ONC theoretically has an EHR performance report but I couldn’t find anything that actually compares features or performance of EHRs. KLAS puts out a report that requires a fee. Much of the information about EHR performance is - surprise! - kept confidential as proprietary information in the certification process.
Thus, we live in a bizarre world in which a piece of software warrants more privacy related to its performance than an individual physician.
In future Substacks, we’ll explore:
Types of healthcare AI evaluations
Publicly available AI evaluations
Human baselining
The power of AI in life sciences lies in its ability to accelerate discovery—whether it’s finding novel drug candidates, predicting disease progression, or personalizing treatments at scale