


Rethinking Risk in Healthcare AI
Why We're Asking the Wrong Questions, and Where to Focus Instead

I’ve always been a terrible surfer. The handful of times I’ve tried, I ended up mostly slamming into the ocean while all my kids somehow glided effortlessly over the waves. It’s not for lack of trying; I’ve watched videos and even taken lessons. Despite my complete lack of aptitude, I appreciate the sport for its clear analogy to life’s unpredictability. No matter how much you know what you’re supposed to do, you can’t predict exactly when the next swell will hit or how big it will be. All you can do is learn to recognize the patterns, adjust your stance, and be ready for whatever comes.
Healthcare AI is much the same. Hospitals are starting to implement healthcare AI applications. But when it comes time for vendors to answer basic governance questions like “What training data did you use?” or “Is the model explainable?”, the responses are often unsatisfying and vague.
Why?
Because these questions are the wrong ones. In a complex, evolving system like healthcare AI, focusing solely on the technology itself is like trying to predict every single wave in the ocean. Instead, we need to understand the underlying currents—the risk categories and domains that can fundamentally disrupt clinical practice.
Approaches to Risk Identification
Earlier this year, Google released An Approach to Technical AGI Safety and Security, which describes in 145 pages the way they think about risk and how to mitigate it. They group risks by how they might be mitigated rather than trying to guess every single risk that might occur in the complexity of the real world:
“it is helpful to identify broad groups of pathways to harm that can be addressed through similar mitigation strategies. Since the focus is on identifying similar mitigation strategies, we define areas based on abstract structural features (e.g. which actor, if any, has bad intent), rather than concrete risk domains such as cyber offense or loss of human control. This means they apply to harms from AI in general, rather than being specific to AGI.”
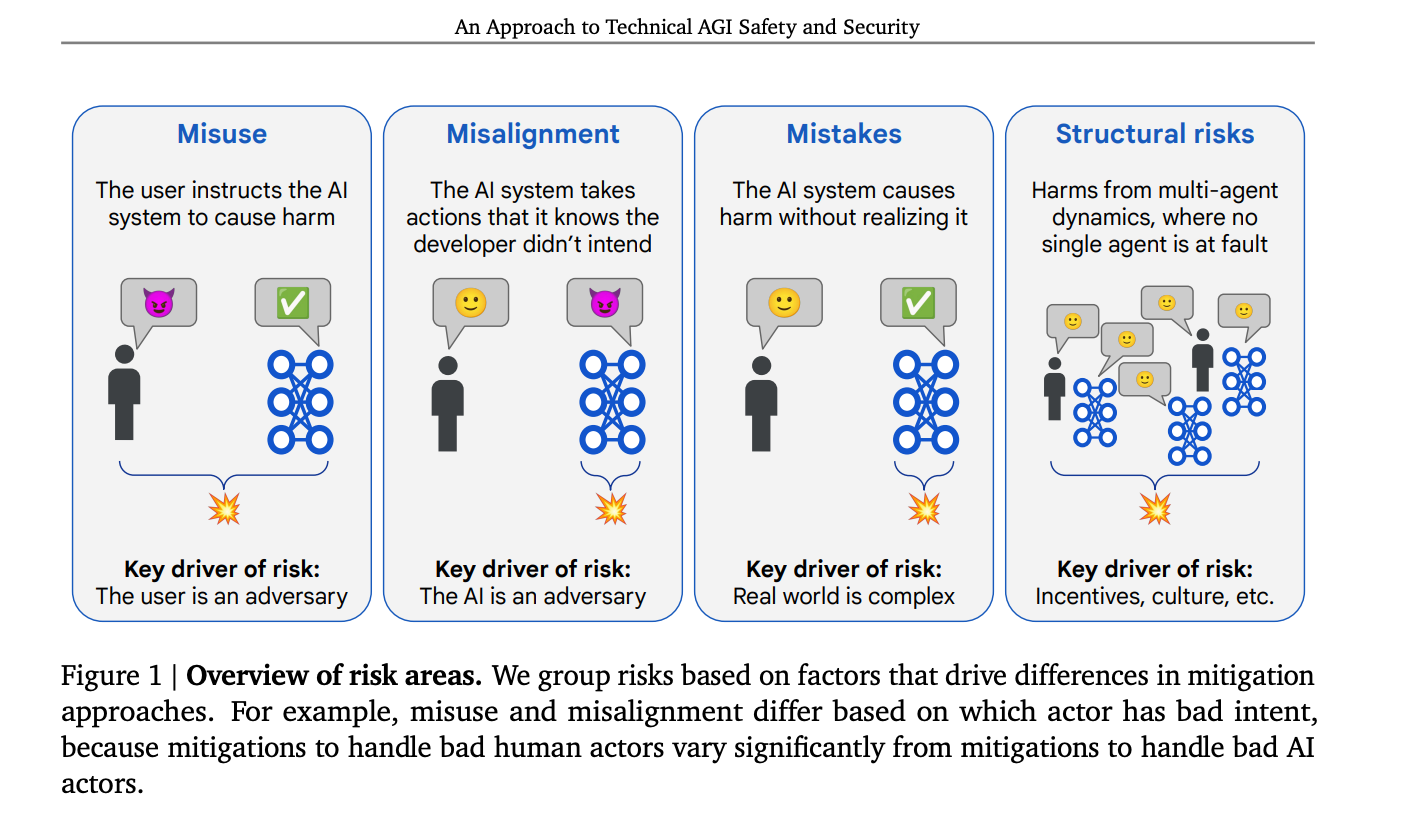
In healthcare, we don’t often use a little devil cat icon (Is it a cat? Or an angry pig?)
Healthcare AI could benefit from a similar shift toward mitigation-based risk grouping. Currently, risk identification in healthcare AI tends to be narrowly focused and static, often linked to the specific technology rather than the broader context of its use. Governance questions often center around technical details, like the training data used or the model’s underlying algorithms. These questions may apply to some, but not situations, and they rarely capture the real-world challenges that arise once the technology is in use.
The Problem with Technology-Specific Risk Thinking
Many of today’s governance frameworks ask questions that feel increasingly irrelevant as AI technology advances. For example, when hospitals evaluate AI tools, they usually include multiple questions about the training data as a way to assess potential bias. But in practice, that focus can be misleading. Consider a dermatology AI model trained predominantly on images of white skin. The problem isn’t just the data itself but the broader domain of subgroup bias. The real question is: How does the model perform across diverse populations?
The root issue is that governance questions are often based on specific technical features rather than broader risk categories. As a result, they fail to adapt as the technology evolves. Instead of focusing on isolated risks, we should be asking: What are the mitigation-based risk categories inherent to any healthcare AI system?
One way to think about mitigations and risk is through the lens of AI biosecurity, which is adapted from a long history of managing biological threats. Instead of predicting every possible failure, AI biosecurity involves identifying potential pathways to harm, as we did in this Nature Communication paper, and building frameworks that can address them regardless of the specific technology involved.
Shifting the Focus to Risk Categories and Domains
I’ve developed a more adaptable approach that I call the Healthcare AI Integrity Framework. Rather than fixating on individual technical flaws, it organizes risks into Domains, which are grouped by the kinds of mitigations that would need to be put into place, and the effects by Impact Dimensions, which are outcome considerations for healthcare interventions.
The Domain categories are Misuse, Mistakes, and Structural Risks. The three Impact Dimensions of Clinical and Safety, Legal and Regulatory, and Reputational and Ethical span the domains. By framing risks in this way, we move from a narrow, technology-specific perspective to one that considers how AI systems integrate into the complex, real-world environment of healthcare.

Domains
Misuse: These risks occur when AI tools are exploited intentionally or through negligence. Financial exploitation, patient data misuse, and user behavioral manipulation fall into this category. These are scenarios where AI is used to maximize profit or control behavior at the expense of patient safety or ethical standards. For example, optimizing documentation to inflate RVUs without clinical necessity is a form of financial exploitation that compromises patient trust.
Mistakes: This category is divided into mistakes by the AI system and mistakes by the user. Mistakes by AI include algorithmic errors, subgroup bias, contextual misunderstandings, and even hallucinations in generative models. Mistakes by users—like clinical overreliance on AI suggestions, data entry errors, and poor workflow integration—can be just as damaging. In practice, these mistakes often manifest as false positives or negatives, mistargeted interventions, or workflow breakdowns that disrupt patient care.
Structural Risks: These are systemic vulnerabilities that emerge from the broader integration of AI into clinical settings. They include multi-agent interactions where different AIs interact in unpredictable ways, systemic workflow failures that create bottlenecks or safety risks, insufficient infrastructure to support meaningful AI deployment, and inadequate governance that leaves gaps in accountability. These risks are less about individual model failures and more about the way AI is embedded into the clinical ecosystem.
Impact Dimensions
Clinical and Safety Risks: These risks address direct impacts on patient outcomes and clinical workflows. For example, algorithmic errors (a Mistake by AI) can lead to missed diagnoses or incorrect treatment recommendations. Human-AI interface errors (a Mistake by the User) can disrupt clinical workflows, leading to delays or miscommunication in patient care. Structural risks, like multi-agent interactions, can compromise clinical decision-making if one AI system's output conflicts with another’s.
Regulatory and Legal Risks: This domain covers compliance with medical regulations, data privacy laws, and standards for clinical validation. Misuse of patient data or financial exploitation by AI tools can result in legal repercussions and breaches of regulatory guidelines. Structural risks like inadequate governance can expose hospitals to fines and legal action if AI-driven decisions violate patient rights or safety standards.
Reputational and Ethical Risks: Trust in healthcare is hard-earned and easily lost. Misuse, like behavioral manipulation or patient data misuse, can rapidly erode patient confidence. Mistakes, especially those that reflect bias or unsafe clinical recommendations, can lead to widespread distrust. Structural failures that result in workflow breakdowns or visible patient harm can damage the reputation of both the technology provider and the healthcare institution.
Note that I did not include misalignment, or the AI system deliberately acting as an “adversary” from Google’s framework. This is a huge area of research but it is out of scope for this discussion. Also note that it might seem like misaligned AI should be the same as AI mistakes, as in “misaligned with goals”. To avoid confusion with the AGI misalignment term that defines it as an AI system as an adversary, I’ve kept “misalignment” to that definition.
The Path Forward
Good surfers don’t try to predict every wave. They study the patterns, anticipate both risks and opportunities, and adapt in real time—shifting their weight, adjusting their stance, and making quick decisions to stay upright. They aren’t trying to control the ocean; they are learning to move with it. That’s exactly what effective governance for healthcare AI should look like. We can’t predict every risk, but we can recognize the domains where failure is most likely, and what impacts that might have, and prepare for those scenarios.
Instead of asking, “How was this model trained?” we should be asking, “What risk domains are inherent to this AI system? How are these risks likely to interact within a clinical setting?” This reframing is more than just a theoretical shift. It can align the questions we’re asking with what we really want to know and make healthcare AI better, safer, and more reliable.