
Healthcare AI job interviews
Healthcare AI job interviews
Can we do a better job interviewing AI systems than we do with humans?

Job interviews of the future
Multiple studies have demonstrated that unstructured interviews are useless for predicting how good a person will be at their job. One of the main studies that showed this was a study of applicants who were admitted to the University of Texas-Houston medical school. The first batch of students was admitted with interviews, then the Texas legislature ordered the school to accept another 50 students. UT-Houston admitted the next 50 students in their rank list, who had been interviewed but were initially rejected. A study done afterwards showed no difference in metrics of success between the first batch and second batch of students. In other words, the interviews hadn’t helped at all. There is some evidence that very structured interviews may help predict performance (but that previous job experience doesn’t).
Now let’s think about how we hire people in medicine.
Scenario 1: Imagine you wanted to hire a medical scribe. You put out a request for applications, read through several CVs, and have preliminary phone conversations with the candidates who seem most promising.
Let’s say you’re being extra thorough and put them through a dictation test before you hire them. That would be an impressive level of due diligence. You’d create a sample visit and have them fill in a chart based on that visit, and choose the one who did the best. That would be amazing, wouldn’t it?
Scenario 2: Imagine you want to hire a new cardiologist who would focus exclusively on consults for triage of cardiac patients across your large hospital system. You’d again put out a request for applications, read through several CVs, and have preliminary phone conversations with the candidates who seemed most promising.
Because you’re being extra thorough these days, you even devise a series of clinical scenarios and ask each candidate to diagnose the condition and make preliminary recommendations. Again, amazing! Everyone would be so impressed with your approach!
The likelihood of this level of testing is low in Scenario 1 and basically unheard of for Scenario 2. (Note that in engineering it’s relatively common to have ‘job tests’ for engineering skills, though they often pay for the candidates’ time to complete them). These kinds of tests are time-consuming for both the interviewee and the company hiring, require the hiring company to devise, score and possibly validate the tests, and would still likely miss significant nuance (what if one candidate could scribe in both English and Spanish, for example, but your test is only in English?)
Benchmarks for job interviews
But imagine if there was a benchmark to determine how good these candidates are, and that the candidates had unlimited time to take these kinds of tests. AI systems can be put through these kinds of “job interviews” much more easily than humans, and the results can be surprising. Some small models like PaLM-2 do better on the science questions than the big general purpose models, for example.

How are they supposed to figure out how good the technology is? What they really want is a public benchmark like the MMLU:
“The benchmark covers 57 subjects across STEM, the humanities, the social sciences, and more. It ranges in difficulty from an elementary level to an advanced professional level, and it tests both world knowledge and problem solving ability. Subjects range from traditional areas, such as mathematics and history, to more specialized areas like law and ethics. The granularity and breadth of the subjects makes the benchmark ideal for identifying a model’s blind spots.”
Different LLMs can demonstrate their abilities on the MMLU, and sometimes it’s surprising: the smaller model outperforms a larger model on a specific aspect, for example.

Now imagine that you’re not just hiring one scribe, but one scribe for the entire health system at once. This one scribe would need to perform well not just in the clinic, but also in the emergency room, labor and delivery, and the ICU. It would need to be fluent in the note templates and terminology in each of those settings. But what if you’re a small hospital and only need the scribes for one setting? Is there an AI scribe that is best at that particular task?
What do hospital administrators need to decide which healthcare AI tools to buy?
You can see how having a benchmark for AI medical scribes would be helpful for a hospital trying to decide which system to buy. The hospital could see how well different models perform at the same task in order to decide which one best suits their needs.
Right now I’d argue that we are “hiring” AI systems based on an unstructured job interview, also known as a sales pitch from the company. We aren’t requiring it to do perform a specific task in a specific way, or comparing its performance to others. Since we have good data about how effective salespeople are from the days of free lunches from drug companies, I think we can assume at least similar effectiveness of AI salespeople for their products. Just like in an unstructured interview, decisions are often more related to a “spark” or a feeling of commonality than a predictor of future performance.
Let’s be honest: the likelihood that clinicians will be the decision-makers for purchasing new healthcare AI technology is somewhat low if we go by historical precedent for EHRs and other technology in hospitals and clinics. It’s going to be hospital administrators, hopefully many of whom are clinicians, who are actually going to buy this technology. They have many aspects to consider when purchasing new software, many of which may not be related to clinical safety or useability. Importantly, they may not know what they should be looking for to evaluate those aspects. For that matter, many clinicians may not know what to ask until they’ve used several of these systems.
Benchmarks would allow hospitals not just to run the tests, but also give them a framework for the kinds of issues they should be focusing on. The CHAI group lists as the important aspects of healthcare AI evaluation, which is wonderful. However, we need to be able to ask questions that are at least one level deeper than these categories: How do I know this AI system is fair? What does fair mean for this particular use case? For an AI scribe, that may mean being able to understand and translate multiple languages. For a diagnostic algorithm, that may be understanding the dataset the AI system was trained on and how representative it is of that particular hospital’s population.
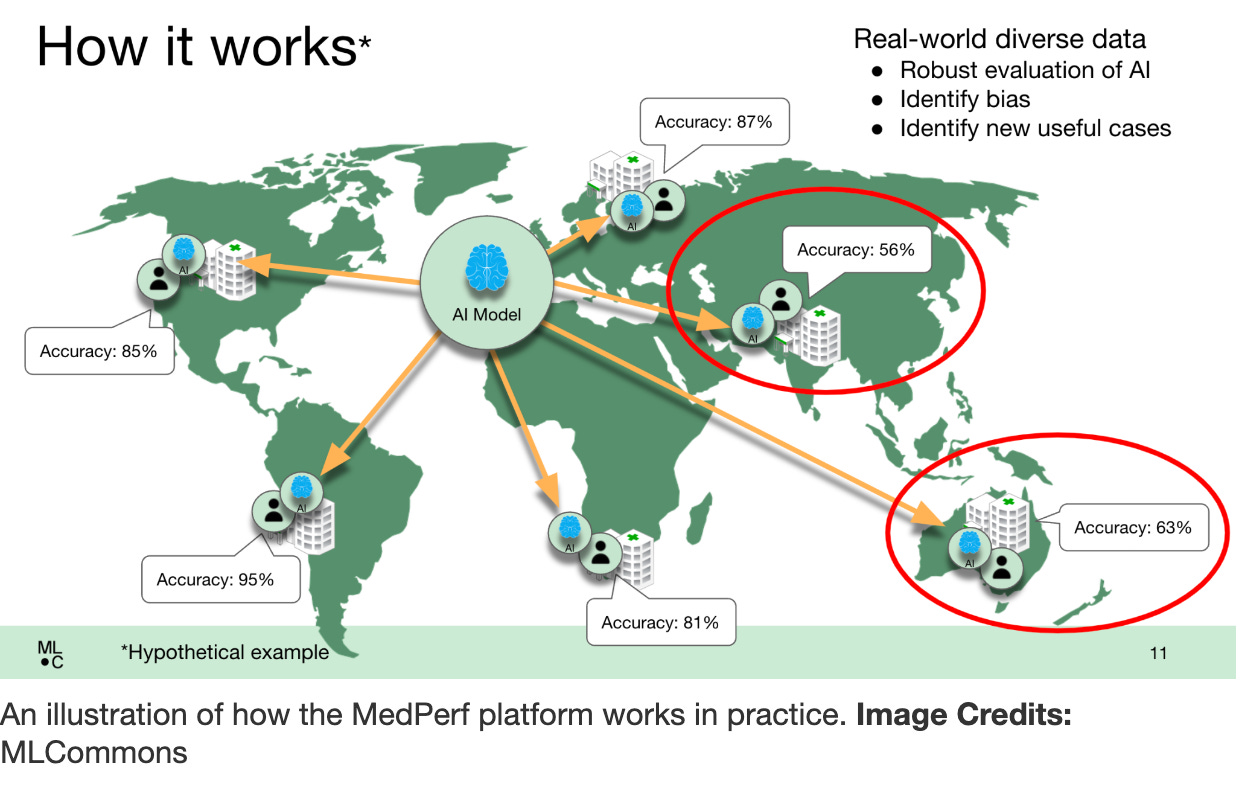
MedPerf
MLCommons has a Medical Working Group that developed MedPerf (I think the name is a little unfortunate since “perf” is much more closely tied to “poking a hole in something by accident” than “performance” in medicine).
They’ve used it to evaluate some tumor registries and look at bias, though it’s mostly being used for AI systems that use AI in radiology currently.
A healthcare AI system registry?
The Coalition for Healthcare AI describes an exciting vision of a registry for AI tools:
“Health care providers with access to information about a patient’s clinical history, phenotype, genotype, etc. can interact with such registries to see if a particular algorithm is likely to perform well.”
This registry doesn’t exist yet, but if it did, CHAI says that “An assurance lab can help ensure that the information on such registries is trustworthy. There can be thousands of data sources that are integrated. The registry of tools can help increase transparency and provide a platform for evaluation rubrics that can inform data and model validation and other aspects necessary for an ecosystem to flourish”.
So perhaps this kind of framework is something to look forward to, though it seems unlikely that this registry is going to be developed and the tools validated in the near future.
Summary
Our patients deserve to have AI systems that are actually good at their jobs. If we don’t know what we’re “interviewing” these systems for, the AI system “job interviews” will be based on sales relationships and cost rather than clinical utility. Without a better understanding of what we want to be measuring with different AI system capabilities, we won’t be able to create meaningful evaluations or benchmarks. And without evaluations or benchmarks, we can’t expect hospital administrators to be able to make well-informed decisions about which AI systems to purchase.