
Federated Learning and Privacy
Federated Learning and Privacy
Can we train models on more data without exposing patient data?

Note: I’m moving to an every other week publishing schedule for now.
In several recent Substacks I discussed the large amount of patient data that’s floating around with for-profit brokers. In the next few articles I’ll discuss some approaches to mitigate privacy concerns with the rise of big data.
Many aspects of daily life now involve sending personal information online. Opening an app in a phone is likely to expose a user to the risk of personal information being hacked, leaked, or exposed somehow. Seventy-eight percent of Americans prefer to bank online, which has similar privacy regulations.
The ubiquity of personal data concerns means that many people in fields outside healthcare are working on approaches to help safeguard data, which is great news. We have experts with zero interest in healthcare who are working on these problems also, which vastly increases the likelihood of some creative solutions. Engineers and experts are developing new approaches for both privacy and security.
Privacy and Security are different
First, let’s clarify how privacy and security are different:
Privacy is the ability to guard an individual’s information or identity
Security is the ability to defend against unauthorized access
You can have security without privacy, but not privacy without security
The International Association of Privacy Professionals (IAPP) defines the difference between data security and privacy in the following way:
“Data privacy is focused on the use and governance of personal data— things like putting policies in place to ensure that consumers’ personal information is being collected, shared and used in appropriate ways.
Data security focuses more on protecting data from malicious attacks and the exploitation of stolen data for profit.
While security is necessary for protecting data, it is not sufficient for addressing privacy.”
The US Department of Health and Human Services (HHS) describes the difference between the HIPAA Security and Privacy Rules with respect to electronic protected health information (EPHI):
“The Privacy Rule sets the standards for, among other things, who may have access to PHI, while the Security Rule sets the standards for ensuring that only those who should have access to EPHI will actually have access…
The key distinction here is that the Security Rule requires protection of sensitive data against unauthorized access, while the Privacy Rule specifies who is granted authorization or has the right to grant authorization.”
What’s wrong with our current approach?
Patient data is inherently risky to aggregate in one place like a data lake (a huge repository of patient data) due to both privacy and security concerns. From a privacy perspective, the risks of re-identification with AI mean that even data that has traditionally been seen as sufficiently ‘cleaned’ may not be adequate to protect privacy. From a security perspective, having a large amount of data in one location makes unauthorized access more likely.
Many companies that hold data don’t want the data centralized for a variety of reasons, many similar to the concerns of hospitals. That means non-healthcare engineers and researchers have been working on this problem for years.
Federated Learning
Federated learning is a privacy-preserving machine learning technique that trains models across decentralized data sources.
Google developed Federated Learning in 2016 to update Android phones without centralizing customer information. The basic premise is that you bring the model to the data instead of the data to the model. Federated learning “transfers the task of data training to each local client, and the communication between client and server is through parameter interaction rather than direct data interaction”.
Broad common Steps of FL:
Hospital downloads the initial common model.
Hospital trains the model on its own data until the local model converges
Hospital sends the encrypted model parameters to the server
The common server uses a FL algorithm to update the global model.
Repeat steps 1-4 until the global federated model converges
For vertical FL, there may be some intermediate steps such as exchanging interim results rather than training parameters

https://www.mdpi.com/2673-4591/59/1/230
Since that initial Google paper, Federated Learning has developed into several other variations for different problems based on how similar the data are and where they’re stored:
Horizontal or vertical FL are used depending on how similar the rows of data are
Also sometimes referred to as homogeneous (horizontal) or heterogeneous (vertical)
Cross-device or cross-silo are used depending on where the information is stored.
For example, these days, the kind of FL described by Google would be considered horizontal and cross-device.
Google’s initial description was horizontal because the (horizontal) rows capture the same data, or features, of information from different places or people.
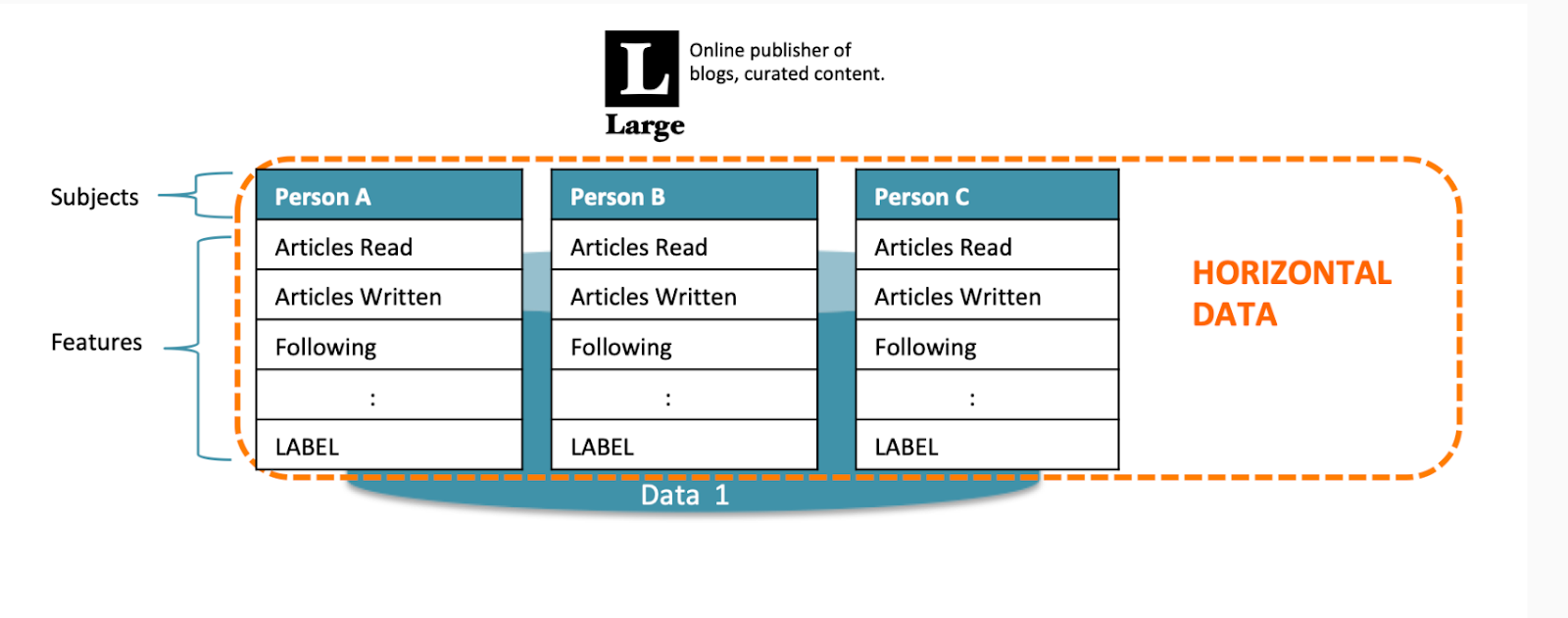
https://blog.openmined.org/federated-learning-types/
Vertical FL, in contrast, is used when you want to combine data about the same people from different sources with different feature rows. In the simple example below, some blog readers have data about the books they bought, and other people don’t. You can imagine how complicated this could become with medical data from different institutions. The training data and iterative loops for vertical FL are also more complicated

https://blog.openmined.org/federated-learning-types/
Google’s initial description was cross-device because the data is coming from different devices.
In healthcare, most of the time you’d be using cross-silo approaches, which use servers at different institutions. Often more of the computing is done locally in the cross-silo approaches because there’s more computing power locally, rather than just a cellphone, for example.
All of the FL approaches above are model-centric, which is currently the most common. New research exploring data-centric FL would allow people who have data, rather than those who have the models, to allow access to their data by the models.
If Federated Learning is so great, why isn’t it everywhere?
Contracts: Federated Learning still requires written agreements amongst institutions (or a terms and conditions contract as in the case of Google). If anyone has ever gone through a hospital contracting process, you know how long this can take. Months to years, in some cases.
Privacy isn’t perfect: There may be more possibility for leakage of personal information than originally understood:
“FL is essentially characterized by exposing certain parameter data and assuming that these data do not reveal sensitive information. However, a growing body of research has found that this hypothesis is not necessarily objective. In FL, there are still hidden dangers of parameters leakage and attack by malicious operations”
Engineering complexity: It’s not simple from an engineering standpoint:
Having a bunch of heterogeneous data is always difficult, often requires data cleaning, and can lead to model drift.
Coordinating engineering including model training and resource allocation can be a challenge
Money: It can be expensive
The overhead of FL from contracting and engineering resources is not insignificant, and can be a barrier
Despite the potentially huge medical benefits of being able to pool data amongst different institutions, there’s no financial incentive or reimbursement path for health systems to do this.
Some inherent challenges are still being worked out:
Single-shot FL, in which the model training doesn’t have to be iterative, is becoming a possibility
There are some newer papers about training asynchronously to accommodate differing schedules including using blockchain as an aggregator
Because all the data are distributed, it’s harder to create a universal security approach to defend the system
Conclusion
Overall, Federated Learning’s promise of allowing access to diverse data repositories without compromising privacy is exciting. Especially in a field like medicine, being able to access data from different institutions could potentially lead to life-saving interventions. I’m hopeful that some of the practical and engineering challenges can be overcome to allow us to capitalize on the possibilities of using more ML approaches that allow for increased patient privacy.